Overview
The following is a simple overview of the main features in Terragrunt.
It includes configurations that are a bit more complex than the ones found in the Quick Start, but don’t panic!
We’ll walk you through each one, and you don’t need to understand everything right away. Knowing that these features are available as you start to use Terragrunt can give you a tool to reach for when you encounter common problems that typically require one or more of these solutions.
This guide is geared towards users who have either already gone through the Quick Start or are joining a team of users that are already using Terragrunt. As a consequence, we’ll be using more complex configurations, discussing more advanced features, and showing how to use Terragrunt to manage real AWS infrastructure.
If you are unfamiliar with OpenTofu/Terraform, you may want to also read OpenTofu or Terraform documentation after reading this guide.
Following Along
Section titled “Following Along”What follows isn’t a tutorial in the same sense as the Quick Start, but more of a guided tour of some of the more commonly used features of Terragrunt. You don’t need to follow along to understand the concepts, but if you want to, you can.
The code samples provided here are available as individual “steps” here.
If you would prefer it, you can clone the Terragrunt repository, and follow along with the examples in your own environment without any copy + paste.
Just make sure to replace the values prefixed __FILL_IN_ with values relevant to your AWS account.
If you don’t have an AWS account, you can either sign up for a free tier account at aws.amazon.com or adapt the examples to use a different cloud provider.
Example
Section titled “Example”Here is a typical terragrunt.hcl file you might find in a Terragrunt project*:
# Configure the remote backendremote_state { backend = "s3"
generate = { path = "backend.tf" if_exists = "overwrite_terragrunt" }
config = { bucket = "my-tofu-state"
key = "tofu.tfstate" region = "us-east-1" encrypt = true dynamodb_table = "my-lock-table" }}
# Configure the AWS providergenerate "provider" { path = "provider.tf" if_exists = "overwrite_terragrunt" contents = <<EOFprovider "aws" { region = "us-east-1"}EOF}
# Configure the module## The URL used here is a shorthand for# "tfr://registry.terraform.io/terraform-aws-modules/vpc/aws?version=5.16.0".## You can find the module at:# https://registry.terraform.io/modules/terraform-aws-modules/vpc/aws/latest## Note the extra `/` after the `tfr` protocol is required for the shorthand# notation.terraform { source = "tfr:///terraform-aws-modules/vpc/aws?version=5.16.0"}
# Configure the inputs for the moduleinputs = { name = "my-vpc" cidr = "10.0.0.0/16"
azs = ["us-east-1a", "us-east-1b", "us-east-1c"] private_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"] public_subnets = ["10.0.101.0/24", "10.0.102.0/24", "10.0.103.0/24"]
enable_nat_gateway = false enable_vpn_gateway = false
tags = { IaC = "true" Environment = "dev" }}Try it out
Section titled “Try it out”If you want to try this configuration locally:
-
Copy the contents above into a
terragrunt.hclfile in an empty directory. -
Change the value of
bucketin theremote_stateblock to a unique name.This has to be globally unique, so you might want to include today’s date in the name.
-
Ensure that you are authenticated with AWS and have the necessary permissions to create resources.
Running
aws sts get-caller-identityin the AWS CLI is a good way to confirm this. -
Run
terragrunt apply -auto-approvein the directory where you created theterragrunt.hclfile.
If you’re familiar with OpenTofu/Terraform, this should be a pretty familiar experience.
For the most part, when you use Terragrunt, you are simply setting up configurations in terragrunt.hcl files that have analogues to what you would define with .tf files, then running terragrunt instead of tofu/terraform on the command line.
terragrunt.hcl
Section titled “terragrunt.hcl”The terragrunt.hcl file above does the following:
Remote state backend configuration
Section titled “Remote state backend configuration”The remote_state configuration block controls how Terragrunt should store backend OpenTofu/Terraform state.
In this example, Terragrunt is being configured to store state in an S3 bucket named my-tofu-state in the us-east-1 region. The state file will be named tofu.tfstate, and Terragrunt will use a DynamoDB table named my-lock-table for locking.
If you run the following, you can see how Terragrunt generates a backend.tf file to tell OpenTofu/Terraform to do this:
$ find .terragrunt-cache -name backend.tf -exec cat {} \;# Generated by Terragrunt. Sig: nIlQXj57tbuaRZEaterraform { backend "s3" { bucket = "my-tofu-state" dynamodb_table = "my-lock-table" encrypt = true key = "tofu.tfstate" region = "us-east-1" }}Right before running any OpenTofu/Terraform command that might store state, Terragrunt will ensure that the appropriate backend.tf file is present in the working directory where OpenTofu/Terraform will run, so that state is persisted appropriately when tofu or terraform are invoked.
Note that while following the example above, you didn’t need to manually create that my-tofu-state S3 bucket, the my-lock-table DynamoDB table, or run tofu/terraform init to perform initialization.
These are just a few of the things that Terragrunt does automatically when orchestrating OpenTofu/Terraform commands because it knows how OpenTofu/Terraform work, and it can take care of some busy work for you to make your life easier.
Provider configuration
Section titled “Provider configuration”The generate block is used to inject arbitrary files into the OpenTofu/Terraform module before running any OpenTofu/Terraform commands.
In this example, Terragrunt is being configured to inject a provider.tf file into the module that configures the AWS provider to use the us-east-1 region.
If you run the following, you can see the provider.tf file that Terragrunt generates:
$ find .terragrunt-cache -name provider.tf -exec cat {} \;# Generated by Terragrunt. Sig: nIlQXj57tbuaRZEaprovider "aws" { region = "us-east-1"}This is the most common use case for the generate block, but you can use it to inject any file you want into the OpenTofu/Terraform module. This can be useful for injecting any configurations that aren’t part of the generic module you want to reuse, or aren’t easy to generate dynamically (such as provider blocks, which can’t be dynamic in OpenTofu/Terraform). You can imagine that it may be convenient to have one set of modules, but dynamically inject different provider configurations based on the AWS region you’re deploying to, etc.
You want to be mindful not to do too much with this configuration block, as it can make your OpenTofu/Terraform code harder to reproduce, understand and maintain. But it can be a powerful tool when used judiciously.
Module configuration
Section titled “Module configuration”The terraform block is used to indicate where to source the OpenTofu/Terraform module from (it’s called terraform for historical reasons, but it controls behavior pertinent to both OpenTofu and Terraform).
In this example, all it is doing is controlling where Terragrunt should fetch the OpenTofu/Terraform module from. The configuration block can do a lot more, but the source attribute is the most common attribute you’ll set on the terraform block.
You’ll notice that in the examples above, we were using find to locate the .tf files being generated and placed within the OpenTofu/Terraform module being downloaded here within the .terragrunt-cache directory. This is because Terragrunt aims to operate as an orchestrator, at a level of abstraction higher than OpenTofu/Terraform.
Over the years supporting customers managing IaC at scale, the patterns that we’ve seen emerge for really successful organizations is to treat OpenTofu/Terraform modules as versioned, generic, well tested patterns of infrastructure, and to deploy them in as close to the exact same way as possible across all uses of them.
Terragrunt supports this pattern by treating each unit of Terragrunt configuration (a directory with a terragrunt.hcl file in it) as a hermetic container of infrastructure that can be reasoned about in isolation, and then composed together to form a larger system of one or more stacks (each stack being a collection of units).
To that end, the way that Terragrunt loads OpenTofu/Terraform configurations is to download them into a subdirectory of the .terragrunt-cache directory, and then to orchestrate OpenTofu/Terraform commands from that directory. This ensures that the OpenTofu/Terraform modules are treated as immutable, versioned, and hermetic, and that the OpenTofu/Terraform runs are reliably reproducible.
Directory.terragrunt-cache/
DirectorytnIp4Am20T3Q8-6FuPqfof-kRGU
DirectoryThyYwttwki6d6AS3aD5OwoyqIWA
- CHANGELOG.md
- LICENSE
- README.md
- UPGRADE-3.0.md
- UPGRADE-4.0.md
- backend.tf
- examples
- main.tf
- modules
- outputs.tf
- provider.tf
- terragrunt.hcl
- variables.tf
- versions.tf
- vpc-flow-logs.tf
Any file that isn’t part of the OpenTofu/Terraform module (like the backend.tf and provider.tf files Terragrunt generated) get a special little Generated by Terragrunt comment at the top of their files by default to make sure it’s clear that Terragrunt generated them (and that they might not be there for other users of the same module).
Inputs configuration
Section titled “Inputs configuration”The inputs block is used to indicate what variable values should be passed to OpenTofu/Terraform when running tofu or terraform commands.
In this example, Terragrunt is being configured to pass in a bunch of variables to the OpenTofu/Terraform module. These variables are used to configure the VPC module, such as the name of the VPC, the CIDR block, the availability zones, the subnets, and so on.
Under the hood, what happens here is that Terragrunt sets relevant TF_VAR_ prefixed environment variables, which are automatically detected by OpenTofu/Terraform as values for variables defined in .tf files.
Further Reading
Section titled “Further Reading”You can learn more about all the configuration blocks and attributes available in Terragrunt in the docs.
Core Patterns
Section titled “Core Patterns”This statement above is kind of a lie:
* Here is a typical terragrunt.hcl file you might find in a Terragrunt project.
The truth is, you’ll almost never see configuration like that outside of some tests or examples. The reason for this is that one of the main responsibilities Terragrunt has is to scale IaC, and the configuration above would result in quite a lot of code duplication across a project. In an AWS project for example, you will probably use the same (or very similar) provider configuration across all your units, and you’ll probably use the same backend configuration across all your units (with the only exception being the key for where in S3 your state should be stored).
Aware of this pattern, Terragrunt is designed to leverage a hierarchy of reusable configurations so that your code can be DRY (Don’t Repeat Yourself).
The include block
Section titled “The include block”In almost every terragrunt.hcl file you see, there will be a section that looks like this:
include "root" { path = find_in_parent_folders("root.hcl")}This block configures Terragrunt to include configuration found in a parent folder named root.hcl into it. This is a way to share configuration across all units of infrastructure in your project.
The root label being applied here is the idiomatic way to reference the root.hcl file that is common to all other configurations in the project. This is a convention, not a requirement, but it’s a good one to follow to make your code more readable and maintainable.
Rewriting the example above to use the include block so that it looks more like the kind of thing you’d see in a real project would look like this:
remote_state { backend = "s3"
generate = { path = "backend.tf" if_exists = "overwrite_terragrunt" }
config = { bucket = "my-tofu-state"
key = "tofu.tfstate" region = "us-east-1" encrypt = true dynamodb_table = "my-lock-table" }}
generate "provider" { path = "provider.tf" if_exists = "overwrite_terragrunt" contents = <<EOFprovider "aws" { region = "us-east-1"}EOF}include "root" { path = find_in_parent_folders("root.hcl")}
terraform { source = "tfr:///terraform-aws-modules/vpc/aws?version=5.16.0"}
inputs = { name = "my-vpc" cidr = "10.0.0.0/16"
azs = ["us-east-1a", "us-east-1b", "us-east-1c"] private_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"] public_subnets = ["10.0.101.0/24", "10.0.102.0/24", "10.0.103.0/24"]
enable_nat_gateway = false enable_vpn_gateway = false
tags = { IaC = "true" Environment = "dev" }}By doing this, you can see that it’s become easier to introduce new units of infrastructure, as you only need to define the unique parts of the configuration for that unit in the new terragrunt.hcl file. The shared configuration is inherited from the root.hcl file.
When you see include blocks in Terragrunt, remember that they result in the configuration being inlined into the configuration file that includes them. For the most part, you can simply replace the relevant include block with the configuration it is including to see the full configuration that Terragrunt will use.
The exception to this is when you are using directives that explicitly leverage the fact that configurations are being included.
Building out the stack
Section titled “Building out the stack”For example, say you wanted to add another unit of infrastructure into the stack that you’re building out here. You could create a new directory named ec2, and add a terragrunt.hcl file to it like this:
include "root" { path = find_in_parent_folders("root.hcl")}
terraform { source = "tfr:///terraform-aws-modules/ec2-instance/aws?version=5.7.1"}
dependency "vpc" { config_path = "../vpc"}
inputs = { name = "single-instance"
instance_type = "t2.micro" monitoring = true subnet_id = dependency.vpc.outputs.private_subnets[0]
tags = { IaC = "true" Environment = "dev" }}Key Collisions
Section titled “Key Collisions”If you tried to run terragrunt plan in that new ec2 directory, you’d get an error that looked like this:
$ terragrunt plan...* Failed to execute "tofu init" in ./.terragrunt-cache/I6Os-7-mjDhv4uQ5iCoGcOrDYhI/pfgqyj3TsBEWff7a1El6tYu6LEE ╷ │ Error: Backend configuration changed │ │ A change in the backend configuration has been detected, which may require │ migrating existing state. │ │ If you wish to attempt automatic migration of the state, use "tofu init │ -migrate-state". │ If you wish to store the current configuration with no changes to the │ state, use "tofu init -reconfigure". ╵
exit status 1What’s happening here is that when Terragrunt invoked OpenTofu/Terraform, it generated exactly the same backend.tf file for the new unit of infrastructure as it did for the VPC unit.
You can see that in the newly generated backend.tf file in the .terragrunt-cache directory under ec2:
$ find .terragrunt-cache -name backend.tf -exec cat {} \;# Generated by Terragrunt. Sig: nIlQXj57tbuaRZEaterraform { backend "s3" { bucket = "my-tofu-state" dynamodb_table = "my-lock-table" encrypt = true key = "tofu.tfstate" region = "us-east-1" }}Dynamic keys
Section titled “Dynamic keys”What most folks would really prefer here is to have the state for the ec2 unit stored in a different, but predictable, location relative to the vpc unit.
The pattern that we’ve found to be most effective is to store state so that the location in the remote backend, like S3 mirrors the location of the unit on the filesystem.
So this filesystem layout:
Directoryroot.hcl
Directoryvpc
- terragrunt.hcl
Directoryec2
- terragrunt.hcl
Would result in this state layout in S3:
Directorys3://my-tofu-state
Directoryvpc
- tofu.tfstate
Directoryec2
- tofu.tfstate
To achieve this, we can take advantage of the path_relative_to_include() Terragrunt HCL function to generate a key dynamically based on the position of the unit relative to the root.hcl file within the filesystem.
remote_state { backend = "s3"
generate = { path = "backend.tf" if_exists = "overwrite_terragrunt" }
config = { bucket = "my-tofu-state"
key = "${path_relative_to_include()}/tofu.tfstate" # <-- region = "us-east-1" encrypt = true dynamodb_table = "my-lock-table" }}
generate "provider" { path = "provider.tf" if_exists = "overwrite_terragrunt" contents = <<EOFprovider "aws" { region = "us-east-1"}EOF}What this does is set the key attribute of the generated backend.tf file to be the relative path from the root.hcl file to the terragrunt.hcl file that is being processed.
Migrating state
Section titled “Migrating state”You have to be careful when adjusting the key attribute of units (including when moving units around in the filesystem, if you use something like path_relative_to_include to drive the value of the key attribute) because it can result in state being stored in a different location in the remote backend.
There’s native tooling in OpenTofu/Terraform to support these procedures, but you want to be confident you know what you’re doing when you run them. By default, Terragrunt will provision a remote backend that uses versioning, so you can always roll back to a previous state if you need to.
# First, we'll migrate state to the new location$ terragrunt init -migrate-state# Then, let's take a look at the generated backend.tf file$ find .terragrunt-cache -name backend.tf -exec cat {} \;# Generated by Terragrunt. Sig: nIlQXj57tbuaRZEaterraform { backend "s3" { bucket = "my-tofu-state" dynamodb_table = "my-lock-table" encrypt = true key = "vpc/tofu.tfstate" region = "us-east-1" }}Now, we can run the plan in the ec2 directory without any issues:
# Within the ec2 directory$ terragrunt plan...$ find .terragrunt-cache -name backend.tf -exec cat {} \;# Generated by Terragrunt. Sig: nIlQXj57tbuaRZEaterraform { backend "s3" { bucket = "my-tofu-state" dynamodb_table = "my-lock-table" encrypt = true key = "ec2/tofu.tfstate" region = "us-east-1" }}Following this pattern, you can create as many units of infrastructure in your project as you like without worrying about collisions in remote state keys.
Note that while this is the idiomatic approach for defining the key attribute for your backend configuration, it is not a requirement. You can set the key attribute to any value you like, and you can use any Terragrunt HCL function to generate that value dynamically such that you avoid collisions in your remote state.
Another completely valid approach, for example, is to utilize get_repo_root, which returns a path relative to the root of the git repository. This, of course, has the drawback that it will not work if you are not using git.
Just make sure to test your configuration carefully, and document your approach so that others can understand what you’re doing.
The dependency block
Section titled “The dependency block”You might have noticed that the ec2 unit of infrastructure has a dependency block in its configuration:
# ...dependency "vpc" { config_path = "../vpc"}
inputs = { name = "single-instance"
instance_type = "t2.micro" monitoring = true subnet_id = dependency.vpc.outputs.private_subnets[0]
tags = { IaC = "true" Environment = "dev" }}This block tells Terragrunt that the ec2 unit depends on the output of the vpc unit. You can also see that it references that dependency within the inputs block as dependency.vpc.outputs.private_subnets[0].
When Terragrunt is performing a run for a dependency, it will first run terragrunt output in the dependency, then expose the values from that output as values that can be used in the dependent unit.
This is a very useful mechanism, as it keeps each unit isolated, while allowing for message passing between units when they need to interact.
The Directed Acyclic Graph (DAG)
Section titled “The Directed Acyclic Graph (DAG)”Dependencies also give Terragrunt a way to reason about the order in which units of infrastructure should be run. It uses what’s called a Directed Acyclic Graph (DAG) to determine the order in which units should be run, and then runs them in that order.
For example, let’s go ahead and destroy all the infrastructure that we’ve created so far:
# From the root directory$ terragrunt run --all destroy16:32:08.944 INFO The stack at . will be processed in the following order for command destroy:Group 1- Module ./ec2
Group 2- Module ./vpc
WARNING: Are you sure you want to run `terragrunt destroy` in each folder of the stack described above? There is no undo! (y/n)First, notice that we’re using a special run --all command for Terragrunt. This command tells Terragrunt that we’re operating on a stack of units, and that we want to run a given OpenTofu/Terraform command on all of them.
Second, notice that the ec2 unit is being run before the vpc unit. Terragrunt knows that the ec2 unit depends on the vpc unit, so it plans to run the ec2 unit first, followed by the vpc unit.
This is a simple example, but as you build out more complex stacks of infrastructure, you’ll find that Terragrunt’s dependency resolution is a powerful tool for getting infrastructure provisioned correctly.
Go ahead and answer y to the prompt to allow destruction to proceed, and notice that the logging has also changed slightly:
16:33:28.820 STDOUT [ec2] tofu: aws_instance.this[0]: Destruction complete after 1m11s16:33:28.936 STDOUT [ec2] tofu:16:33:28.936 STDOUT [ec2] tofu: Destroy complete! Resources: 1 destroyed.16:33:28.936 STDOUT [ec2] tofu:16:33:30.713 STDOUT [vpc] tofu: aws_vpc.this[0]: Refreshing state... [id=vpc-063d11b72a2c9f8b3]16:33:31.510 STDOUT [vpc] tofu: aws_default_security_group.this[0]: Refreshing state... [id=sg-060d402b95a2cd935]16:33:31.511 STDOUT [vpc] tofu: aws_default_route_table.default[0]: Refreshing state... [id=rtb-05adb3ee7f48640f0]Terragrunt will give you the contextual information you need to understand what’s happening in your stack as it’s being run. That [ec2] and [vpc] prefix is a great way to quickly disambiguate what’s happening in one unit of infrastructure from another.
Mock outputs
Section titled “Mock outputs”Now that the stack has been destroyed, take a look at the error you get when you try to run terragrunt run --all plan again:
$ terragrunt run --all plan...16:50:22.153 STDOUT [vpc] tofu: Note: You didn't use the -out option to save this plan, so OpenTofu can't16:50:22.153 STDOUT [vpc] tofu: guarantee to take exactly these actions if you run "tofu apply" now.16:50:22.854 ERROR [ec2] Module ./ec2 has finished with an error16:50:22.855 ERROR error occurred:
* ./vpc/terragrunt.hcl is a dependency of ./ec2/terragrunt.hcl but detected no outputs. Either the target module has not been applied yet, or the module has no outputs. If this is expected, set the skip_outputs flag to true on the dependency block.
16:50:22.855 ERROR Unable to determine underlying exit code, so Terragrunt will exit with error code 1The error emitted here tells us that the vpc unit doesn’t have any outputs available for the ec2 unit to consume as a dependency.
The pattern most commonly used to address this is to simply mock the unavailable output during plans.
Adjust the vpc dependency in the ec2 unit like so:
# ...dependency "vpc" { config_path = "../vpc"
mock_outputs = { private_subnets = ["mock-subnet"] }
mock_outputs_allowed_terraform_commands = ["plan"]}# ...Then run the plan again:
$ terragrunt run --all plan...16:53:04.037 STDOUT [ec2] tofu: + source_dest_check = true16:53:04.037 STDOUT [ec2] tofu: + spot_instance_request_id = (known after apply)16:53:04.037 STDOUT [ec2] tofu: + subnet_id = "mock-subnet"16:53:04.037 STDOUT [ec2] tofu: + tags = {16:53:04.038 STDOUT [ec2] tofu: + "Environment" = "dev"...As you can see, the plan for the EC2 instance now includes a subnet_id value of mock-subnet, which is the value we provided in the mock_outputs block.
Terragrunt only uses these mock values when the output is unavailable, so a terragrunt run --all apply would succeed, but it’s best practice to explicitly tell Terragrunt that it should only use these mock values during a plan (or any other command where you are okay with the output being mocked).
Also note that when you run terragrunt run --all apply:
$ terragrunt run --all apply16:57:32.297 INFO The stack at . will be processed in the following order for command apply:Group 1- Module ./vpc
Group 2- Module ./ec2
Are you sure you want to run 'terragrunt apply' in each folder of the stack described above? (y/n)That the order of units has flipped. Terragrunt knows that during applies, dependencies actually need to be run before the dependent unit, so it’s flipped the order of the units in the stack, relative to destroys.
You can answer y to allow the apply to proceed and see that the EC2 instance is placed into a real subnet (not the mock value) as expected.
Configuration hierarchy
Section titled “Configuration hierarchy”Terragrunt also provides tooling for constructing a hierarchy of configurations that can be used to manage multiple environments, regions, or accounts.
Say, for example, you wanted to provision the same resources you’ve provisioned so far, but in multiple AWS regions, with a filesystem layout like this:
- root.hcl
Directoryus-east-1
Directoryvpc
- terragrunt.hcl
Directoryec2
- terragrunt.hcl
Directoryus-west-2
Directoryvpc
- terragrunt.hcl
Directoryec2
- terragrunt.hcl
With Terragrunt, that’s pretty easy to achieve. You would first create a us-east-1 directory like so:
mkdir us-east-1Then move the contents you have in the vpc and ec2 directories into the us-east-1 directory:
mv vpc/ ec2/ us-east-1/Remember that now you’ll need to migrate state, as changing the location of the units in the filesystem will result in a change in the remote state path:
(In production scenarios, you likely want to carefully manage state by migrating over one unit at a time, but for the sake of this tutorial, you can learn about this shortcut)
terragrunt run --all -- init -migrate-stateWe want the AWS region used by our units to be determined dynamically, so we can add a configuration file to the us-east-1 directory that looks like this:
locals { region = "us-east-1"}Then update the root.hcl like so:
locals { region_hcl = find_in_parent_folders("region.hcl") region = read_terragrunt_config(local.region_hcl).locals.region}
# Configure the remote backendremote_state { backend = "s3" generate = { path = "backend.tf" if_exists = "overwrite_terragrunt" } config = { bucket = "my-tofu-state"
key = "${path_relative_to_include()}/tofu.tfstate" region = "us-east-1" encrypt = true dynamodb_table = "my-lock-table" }}
# Configure the AWS providergenerate "provider" { path = "provider.tf" if_exists = "overwrite_terragrunt" contents = <<EOFprovider "aws" { region = "${local.region}"}EOF}Now, when the configurations in the us-east-1 directory include the root.hcl, they’ll automatically parse the first region.hcl file they find while traversing up the filesystem, and use the region value defined in that file to set the AWS region for the provider.
NOTE In the generate block, we’re using "${local.region}", rather than local.region. This is because the generate block is going to generate a file directly into the OpenTofu/Terraform module. We need to ensure that when the value is interpolated, it’s done so in a way that OpenTofu/Terraform can understand, so we wrap it in quotes.
ALSO NOTE The remote_state block is still storing all state in the us-east-1 region by design. We don’t have to do this, and you could easily set it to store state in multiple regions. For the sake of simplicity, and demonstration, we’re keeping it in one region.
Exposed includes
Section titled “Exposed includes”Before moving on, take note of one thing, the azs attribute in the vpc unit of the us-east-1 stack is hardcoded to ["us-east-1a", "us-east-1b", "us-east-1c"].
This would cause issues if we were to try to deploy the vpc unit in the us-west-2 stack, as those availability zones don’t exist in the us-west-2 region. What we need to do is make the azs attribute dynamic and use the resolved region to determine the correct availability zones.
To do this, we can expose the attributes on the included root configuration by setting the expose attribute to true:
include "root" { path = find_in_parent_folders("root.hcl") expose = true}
locals { region = include.root.locals.region}
# Configure the module# The URL used here is a shorthand for# "tfr://registry.terraform.io/terraform-aws-modules/vpc/aws?version=5.16.0".# Note the extra `/` after the protocol is required for the shorthand# notation.terraform { source = "tfr:///terraform-aws-modules/vpc/aws?version=5.16.0"}
# Configure the inputs for the moduleinputs = { name = "my-vpc" cidr = "10.0.0.0/16"
azs = ["${local.region}a", "${local.region}b", "${local.region}c"] # <-- private_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"] public_subnets = ["10.0.101.0/24", "10.0.102.0/24", "10.0.103.0/24"]
enable_nat_gateway = false enable_vpn_gateway = false
tags = { IaC = "true" Environment = "dev" }}This makes it so that the values of the azs attribute are determined dynamically based on the region that the unit is being deployed to.
Now that you’ve set up the us-east-1 directory, you can repeat the process for the us-west-2 directory:
cp -R us-east-1/ us-west-2/Then update the region.hcl file in the us-west-2 directory to set the region to us-west-2:
locals { region = "us-west-2"}Tightening the blast radius
Section titled “Tightening the blast radius”Run the terragrunt run --all apply command after changing your current working directory to the us-west-2 directory:
cd us-west-2terragrunt run --all applyYou should see the VPC and EC2 instances being provisioned in the us-west-2 region.
This showcases three superpowers you gain when you leverage Terragrunt:
- Automatic DAG Resolution: No configuration file had to be updated or modified to ensure that the
ec2unit was run after thevpcunit when provisioning theus-west-2stack. Terragrunt automatically resolved the dependency graph and ran the units in the correct order. - Dynamic Configuration: The code you copied from the
us-east-1directory to theus-west-2directory didn’t need to be modified at all to provision resources in a different region (with the exception of naming the region in theregion.hclfile). Terragrunt was able to dynamically resolve the correct configuration based on context, and apply it to the OpenTofu/Terraform modules as generic patterns of infrastructure. - Reduced Blast Radius: By applying Terragrunt within the
us-west-2directory, you were able to confidently target only the resources in that region, without affecting the resources in theus-east-1region. This is a powerful tool for safely managing multiple environments, regions, or accounts with a single codebase. Your current working directory when using Terragrunt is your blast radius, and Terragrunt makes it easy to manage that blast radius effectively.
Cleanup
Section titled “Cleanup”If you still have all the resources that were provisioned as part of this tutorial active, this is a reminder that you might want to clean them up.
To destroy all the resources you’ve provisioned thus far, run the following:
# From the root directory$ terragrunt run --all destroyIn real-world scenarios, it’s generally advised that you plan your destroys first before cleaning them up:
# From the root directory$ terragrunt run --all -- plan -destroyYou won’t need to run any more Terragrunt commands for the rest of this guide.
Recommended Repository Patterns
Section titled “Recommended Repository Patterns”Outside of the patterns used for setting up Terragrunt configurations within a project, there are are also some patterns that we recommend for managing one or more repositories used to manage infrastructure. At Gruntwork, we refer to this as your “Infrastructure Estate”.
These recommendations are merely guidelines, and you should adapt them to suit your team’s needs and constraints.
infrastructure-live
Section titled “infrastructure-live”The core of the infrastructure you manage with a Terragrunt is typically stored in a repository named infrastructure-live (or some variant of it). This repository is where you store the Terragrunt configurations used for infrastructure that is intended to be “live” (i.e. provisioned and active).
Most successful teams stick to Trunk Based Development, perform plans on any change being proposed via a pull request / merge request, and only apply changes to live infrastructure after a successful plan and review.
This repository is generally concerned with the configuration of reliably reproducible, immutable and versioned infrastructure. You generally don’t author OpenTofu/Terraform code directly into it, and you apply appropriate branch protection rules to ensure that changes are merged only if they get the appropriate sign-off from responsible parties.
What’s on the default branch for this repository is generally considered the source of truth for the infrastructure you have provisioned. That default branch is generally the only version that matters when considering the state of your infrastructure.
You can see an example of this in the terragrunt-infrastructure-live-stacks-example repository maintained by Gruntwork.
infrastructure-modules
Section titled “infrastructure-modules”The patterns for your infrastructure you want to reliably reproduce. This repository is where you store the OpenTofu/Terraform modules that you use in your infrastructure-live repository.
This repository is generally concerned with maintaining versioned, well tested and vetted patterns of infrastructure, ready to be consumed by the infrastructure-live repository.
You typically integrate this repository with tools like Terratest to ensure that every change to a module is well tested and reliable.
Semantic Versioning is widely used to manage communicating the impact of updates to this repository, and you typically pin the version of a consumed module in the infrastructure-live repository to a specific tag.
You can see an example of this in the terragrunt-infrastructure-catalog-example repository maintained by Gruntwork.
Atomic Deployments
Section titled “Atomic Deployments”Following the repository patterns outlined above, you typically see Terragrunt repositories that have configurations which look like this:
include "root" { path = find_in_parent_folders("root.hcl")}
terraform { source = "github.com:foo/infrastructure-modules.git//app?ref=v0.0.1"}
inputs = { instance_count = 3 instance_type = "t2.micro"}Where app is an opinionated module in the infrastructure-modules repository, maintained by the team managing infrastructure for the foo organization.
The code in that module might be hand-rolled, it may wrap a community maintained module, or it might wrap a module like one found in the Gruntwork IaC Library.
Regardless, the module is something that the team managing infrastructure for an organization has vetted for deployment.
When deploying a change to live infrastructure, the team would typically make a change like the following:
include "root" { path = find_in_parent_folders("root.hcl")}
terraform { source = "github.com:foo/infrastructure-modules.git//app?ref=v0.0.2" # <--}
inputs = { instance_count = 1 instance_type = "t3.micro"}Given that all the changes here are part of one atomic deployment, it’s fairly easy to determine the impact of the change, and to roll back if necessary.
After that, they would propagate the change up however many intermediary environments they have, and finally to production.
include "root" { path = find_in_parent_folders("root.hcl")}
terraform { source = "github.com:foo/infrastructure-modules.git//app?ref=v0.0.2" # <--}
inputs = { instance_count = 3 instance_type = "t3.large"}Note that the two terragrunt.hcl files here have different inputs values, as those values are specific to the environment they are being deployed to.
The end result of this process is that infrastructure changes are atomic and reproduceable, and that the infrastructure being deployed is versioned and immutable.
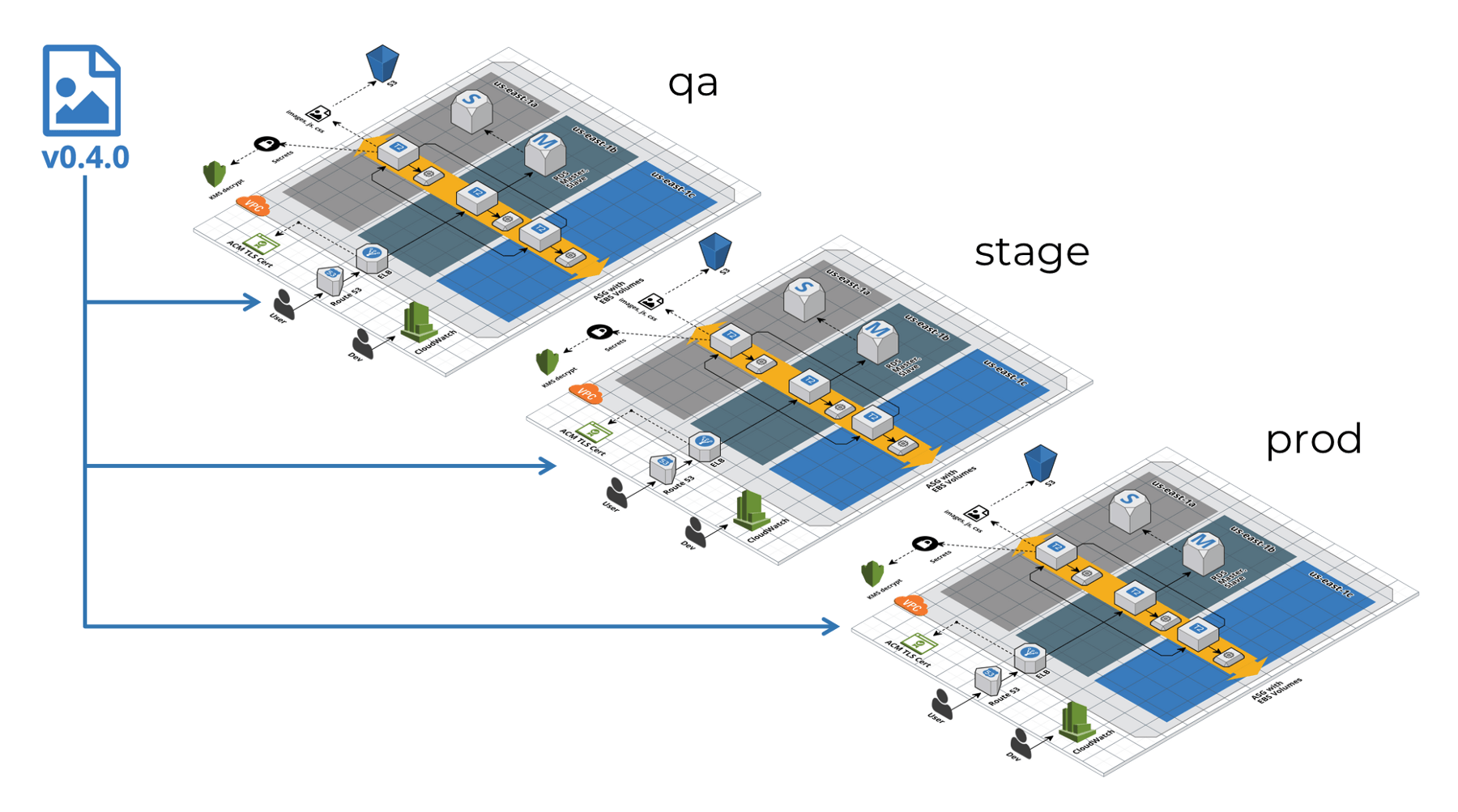
If at any point during this process a change is found to be problematic, the team can simply roll back to the previous version of the module for a single unit in a given environment.
That’s the power of reducing your blast radius with Terragrunt!
Keep It Simple, Silly
Section titled “Keep It Simple, Silly”One last pattern to internalize is the general tendency to prefer simple configurations over complex ones when possible.
Terragrunt provides a lot of power and flexibility, but it’s generally best to use that power to make your configurations more readable and maintainable. Keep in mind that you’re writing code that will be read by other humans, and that you might not be around to explain any complexity you introduce.
As an example, consider one potential solution to a step outlined in the Exposed includes section, the requirement to update the region local in the region.hcl file:
locals { region = "us-west-2"}You might think to yourself “Hey, I know a lot about Terragrunt functionality, I can make this more dynamic, such that I don’t even need to create a region.hcl file!” and come up with a solution like this:
locals { region = split("/", path_relative_to_include())[0]}
# Configure the remote backendremote_state { backend = "s3" generate = { path = "backend.tf" if_exists = "overwrite_terragrunt" } config = { bucket = "my-tofu-state"
key = "${path_relative_to_include()}/tofu.tfstate" region = "us-east-1" encrypt = true dynamodb_table = "my-lock-table" }}
# Configure the AWS providergenerate "provider" { path = "provider.tf" if_exists = "overwrite_terragrunt" contents = <<EOFprovider "aws" { region = "${local.region}"}EOF}This would result in the region local being set to the name of the first directory in the path to the terragrunt.hcl file that is being run during an include (us-east-1 and us-west-1 in each respective stack). This would allow you to remove the region.hcl file from both the us-east-1 and us-west-2 directories.
Consider, though, that this might make the configuration harder to understand for someone who is not as familiar with Terragrunt as you are. You’ve now tightly coupled the name of the directory to the region that the infrastructure is being deployed to, and you’ve made it harder for someone to understand if they run into issues.
Say a user tries to deploy infrastructure while on a Windows machine, where the path separator is \ instead of /. Using this configuration would result in the region local being set to something like us-east-1\vpc, which is confusing and not what you want.
In this case, you might prefer to have kept the region.hcl file, as it makes the configuration more explicit and easier to understand.
On the other hand, maybe you work with a team that’s very comfortable with Terragrunt, exclusively using Unix-based systems, and you’ve all agreed and documented this as a good pattern to follow. In that case, this might be a perfectly acceptable solution.
You have to exercise your best judgment when deciding how much complexity to introduce into your Terragrunt configurations. As a general rule, the best patterns to follow are the ones that are easiest to reproduce, understand, and maintain.
Next steps
Section titled “Next steps”Now that you’ve learned the basics of Terragrunt, here is some further reading to learn more:
-
Features: Learn about the core features Terragrunt supports.
-
Documentation: Check out the detailed Terragrunt reference documentation.
-
Fundamentals of DevOps and Software Delivery: Learn the fundamentals of DevOps and Software Delivery from one of the founders of Gruntwork!
-
Terraform: Up & Running: Terragrunt is a direct implementation of many of the ideas from this book.